
.webp)




However, if there’s one thing that Terraform is prone to, it’s a lack of DRYness (as in Don’t Repeat Yourself). To help solve that, entire frameworks have been created.
Terraform has some features to help with DRYing out your Terraform code, such as reusing files with Terraform modules, and using input variables in order to apply the same stack with minor differences. But those features have their own limitations, and in some use cases they do not give a good solution out-of-the-box.
In this blog post, we will discuss Terraform’s input variables, and their limitations. Specifically, we will focus on the input variables of root modules.
What are Terraform Variables?
Terraform variables allow you to reuse the same Terraform stack with changed configuration. They are pretty similar to input variables in any other programming language: you use input variables to assign dynamic fields to your resource, or even use them for some more complicated logic.
A variable supports the following fields:
- [.code]default[.code] - Provides a default value for a variable. This makes the variable optional.
- [.code]type[.code] - Specifies value types that are accepted for the variable. Some examples are [.code]string[.code], [.code]number[.code] and [.code]list[.code].
- [.code]description[.code] - Specifies documentation for the variable.
- [.code]validation[.code] - Specifies validation rules for the variable.
- [.code]sensitive[.code] - Marks the variable as sensitive. This value will be redacted in Terraform logs.
- [.code]nullable[.code]- Specifies if the variable can be null
In Terraform root modules, variables must be explicitly set (unless a default value is provided). We can do this either before the execution of our terraform command, using environment variables, or by using options when running the command.
This means that for our automation pipeline, we’ll need to manage those variables and supply them to the Terraform CLI with one of the methods mentioned above.
There are a lot of ways to manage Terraform Variables, depending on the complexity of the configuration. We will discuss those methods by analyzing an example use case.
Our Use Case - Terraform Variable Hierarchy
For our use case, let’s look at the following basic example.
We have a Terraform file representing some server’s EC2 instance. In this file we’ll configure the following via variables:
- The AWS region
- The instance’s name
- The instance’s type
- Number of CPU cores
- Stage (added as a tag)
Now let’s say we want to use this specific Terraform root module in order to manage all of our instances, in all regions and stages.
Our infrastructure might look like:
- 2 instances for staging instances in eu-central-1 region, one small, one medium
- 2 instances for staging instances in us-east-1 region, one medium, one large
- 4 instances for production instances in eu-central-1 region, two small, two medium
- 4 instances for production instances in us-east-1 region, two medium, two large
If we want to use our module for that, then every instance would be a separate workspace, and would require different input variables to be applied correctly.
How could we manage our configuration, so that we’d be able to manage our workspaces in a DRY manner?
Using Manual Terraform apply
When we run our first [.code]terraform apply[.code] command on a module with variables, there will be a prompt for values of the variables.
This is the most basic way of providing variable values. But this is just friction when we’re talking about an automation pipeline.
So what are our approaches for providing variable values in an automation pipeline?
Using -var
The most basic way of providing a single variable override for the [.code]terraform apply[.code] command is using the [.code]-var[.code] option to provide a variable value.
In our case, we could run the following command to apply the configuration to a workspace:
[.code]terraform apply -var region=”us-east-1” -var stage=”production” -var instance_type=”t3.large” …[.code]
In a pipeline we could use the [.code]-var[.code] option by creating some environment variables, using them in the command like so: [.code]terraform apply -var region=”$MY_REGION” -var stage=”$MY_STAGE” -var instance_type=”$MY_INSTANCE_TYPE” …[.code]
In an automation pipeline, we’d have to pick environment variables for each workspace. A downside of this approach would be the need to duplicate a lot of configuration between Terraform workspaces. If the automation pipeline supports some sort of variable hierarchy and overrides, then it can help with deduplication.
Using TF_VAR
If our runtime environment has an environment variable prefixed with [.code]TF_VAR_[.code], then Terraform CLI can automatically use it as an input variable. So, if we define an environment variable called [.code]TF_VAR_region[.code], then Terraform will use its value as the value of the variable named [.code]region[.code].
When looking at our specific use case, we’d have to set the following environment variables: [.code]TF_VAR_region[.code], [.code]TF_VAR_stage[.code] and [.code]TF_VAR_instance_type[.code].
This is an acceptable alternative to only using the [.code]-var[.code] option. This way, we don’t have to use any variable related option with the terraform command. We can just run [.code]terraform apply[.code], and Terraform CLI will resolve the variables for us.
As with the [.code]-var[.code] option, we’d still need to pick our environment variables per workspace, and manage the variables in the automation pipeline.
Example - Using tfvars Files
tfvars files are basically variable definition files that specify Terraform variables and values. A tfvar file’s name must end with either a .tfvars or a .tfvars.json suffix.
You could load a tfvar file explicitly by specifying it with the [.code]-var-file[.code] option. For example:
And then run:
Terraform CLI automatically loads tfvars files with the following naming conventions:
- Files named terraform.tfvars or terraform.tfvars.json
- Filenames ending with .auto.tfvars or .auto.tfvars.json
As there are many sources for supplying Terraform variable values, Terraform CLI has a set order for determining which source should take precedence. For example, a [.code].auto.tfvars[.code] file overwrites variables defined in a [.code]terraform.tfvars[.code] file, and a [.code]-var[.code] or a [.code]-var-file[.code] option overwrites variables defined in a [.code].auto.tfvars[.code] file. You can read more about variable definitions precedence here.
A [.code]terraform.tfvars[.code] file could define some default values for our workspace, which may later be modified by a [.code]-var[.code] or [.code]-var-file[.code] options, for example.
We could also have some predetermined tfvars files in our code. For example, we could have a us.tfvars file and an eu.tfvars file, containing a preferred AWS region. We could also create files called small.tfvars, medium.tfvars and large.tfvars to store variables for instance presets.
These could then be used with our Terraform command:
This gives a Terraform integrated way of using preset variables. In a pipeline, we’d still need to figure out which presets should be used for each workspace.
Workspace-based Configuration
Another possibility is to avoid using input variables altogether. We can create a YAML configuration file per workspace, and have Terraform load it dynamically.
Let’s say our workspace name is “us-prod-billing”, and we have a corresponding configuration file in [.code]variables/config-us-prod-billing.yaml[.code]. We could use this configuration in our Terraform code:
Now variables can be used as follows: [.code]local.vars.region[.code]
The major advantage of this approach is that the configuration is fully managed as code. However, it might be prone to runtime failures if the configuration file doesn’t exist or is malformed.
It also doesn’t help with reducing configuration duplication. For every new workspace we’d need to create a new file and copy all relevant variables into it.
Also, if your variables contain sensitive information, then this approach (as well as using tfvars files), would be ill-advised. Since these files are usually committed to a git repository, naturally you do not want sensitive variables committing to version control too!
An alternative approach could be to not expose sensitive values as variables, and instead fetch them at apply time, using a Terraform data source (Such as aws_secretsmanager_secret_version, if you are using AWS Secrets Manager for secrets storage).
Example - Staying DRY with Terragrunt
Terragrunt is a wrapper for Terraform that gives us a lot of extra tools that are missing from Terraform itself. It provides features that help keep your Terraform configuration stay DRY.
Terragrunt can give the best of both worlds. Configuration can have a clear hierarchy, and it remains managed as code.
In Terragrunt, our project folder structure could look something like:
Each region.hcl and stage.hcl file would contain the relevant variables for that specific region/stage:
The root terragrunt.hcl would get the region and stage info from the relative region.hcl and stage.hcl files:
The instance-specific variables could be defined in a preset HCL file, like large-instance.hcl:
And now, each specific Terragrunt module would get the configuration for the root terragrunt.hcl, and any other relevant configuration, and include the actual terraform module for the instance:
Done!
Now each specific terragrunt.hcl file we apply will have its own configuration predetermined by code. It takes all configurations defined in its folder structure and also takes a specific present as additional configuration for the instance.
As you can see, it took us some work in Terragrunt to achieve a framework that allows for easy and DRY configuration management. For simpler configurations, we might consider this overkill which will introduce some complexity.
As with the previous approach, having sensitive variables in files in your git repository is ill-advised. Either provide sensitive values explicitly at apply-time, or fetch them from a secrets store in the Terraform code.
How We Do It With env0
env0 was built with variable management in mind. We understand that variable management with Terraform can sometimes be a pain.
We tried to find a balance between simplicity and flexibility for configuration management, so that configuration setup would be easy to start, but would also allow overrides as necessary.
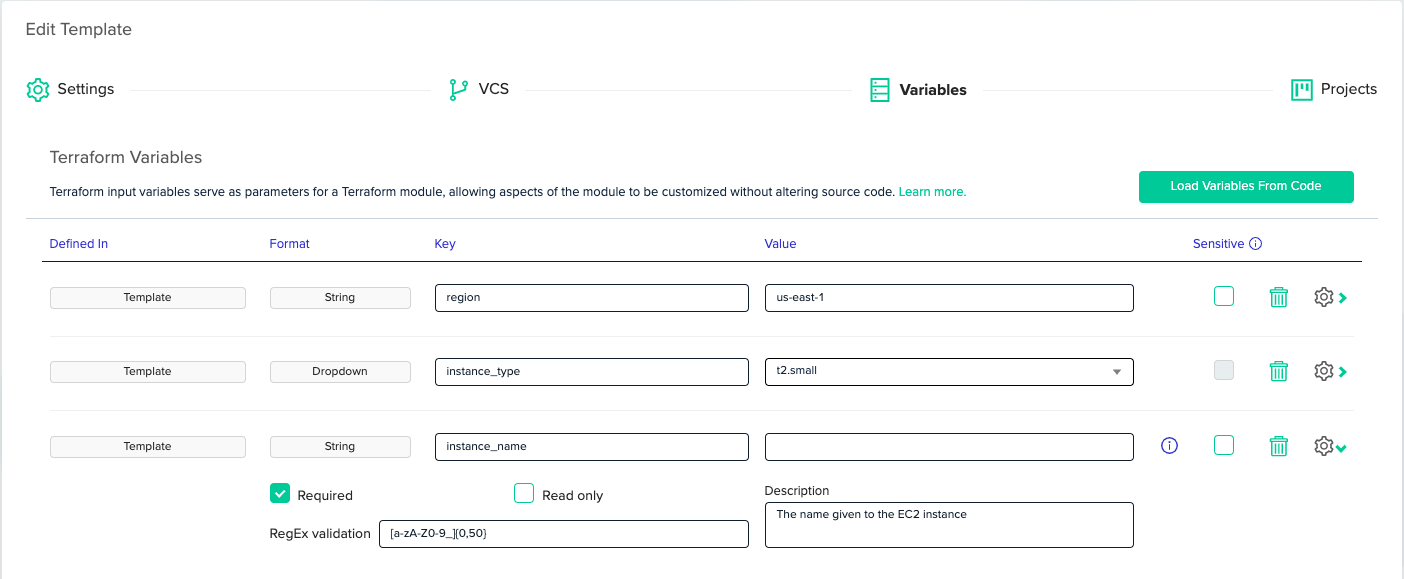
In env0, root modules are called 'Templates'. When using the app, you can click the 'Load Variables From Code' button to load the variable definitions from the [.code]variable[.code] blocks into env0. env0 fetches the variables’ names, descriptions, default values, and types, and populates them into the UI. Then you can use the UI to change the variables’ default values, or enforce a policy on them.
In the following example, [.code]instance_name[.code] is “Required”, meaning env0 will not allow us to apply the workspace until we provide this value. It also has a 'RegEx Validation', so the value of the variable must match the regular expression. It also has a description, documenting its purpose.
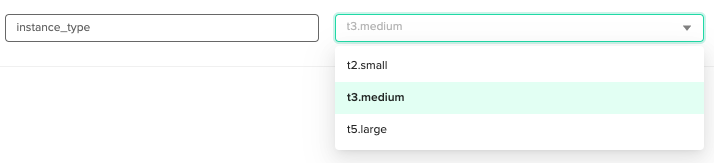
For [.code]instance_type[.code], we’ve set the configuration as a dropdown list with possible choices. So when we apply the workspace, we can pick the instance type from a closed list.
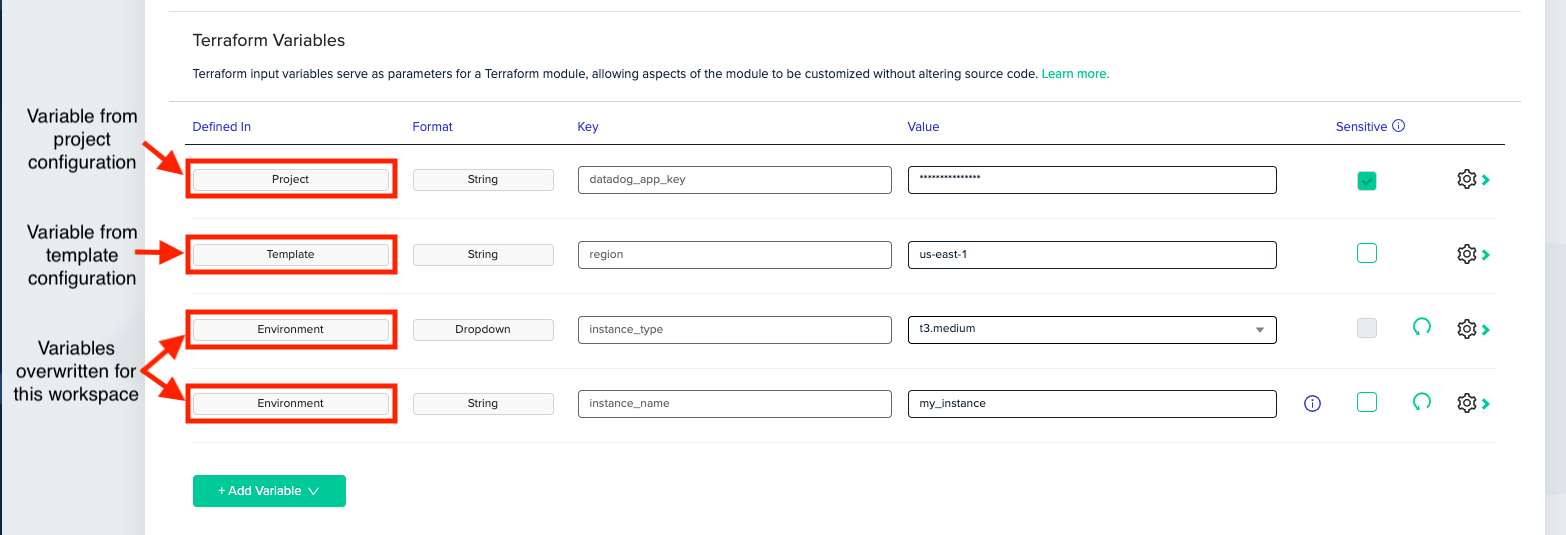
In env0, workspaces are managed inside a project, and projects are managed as part of an organization. An organization can have multiple projects under it, and a project can hold multiple workspaces. Projects are used to better consolidate workspaces and configuration. For example, we might want to separate projects by region, by application, or by cloud account.
We can use the organization and projects to share configuration easily. We can create a "Production” project, and set [.code]stage[.code] there to be [.code]”staging”[.code] for example.
When we are about to apply our Terraform/Terragrunt template in env0, we’ll be able to see all the variables that will be applied, including all overrides:
env0 provides additional configuration management capabilities, like the ability to mark terraform variables as sensitive, making them encrypted in transit and at-rest, and their value won’t be available in the UI, API or the logs. env0 also allows you to set cloud credentials explicitly per project, replacing the need for configuring credentials with environment variables.
An extra benefit of using env0 is that Terraform variables can be managed as code, using our Terraform provider. We could create a “management” workspace in env0 that will be in charge of an entire env0 configuration. Yes, manage env0 with env0!
Final words
Although Terraform provides multiple ways for setting variable values and overwriting them, managing Terraform configuration in an automation pipeline can still be time-consuming.
If a configuration is not too complicated, it might just be simpler to put all variables inline in each workspace. But usually some sort of configuration hierarchy is required, then Terragrunt can help keep code DRY.
The extra challenges that arise when managing configuration inside a CI/CD platform can be solved quickly and easily with env0.
Try it, and let us know your thoughts on Twitter, or via good old email to hello@env0.com.Terraform is one of the most popular infrastructure-as-code tools on the market, with many significant advantages, such as the flexibility to manage all of your cloud infrastructure, no matter the cloud provider, and even enabling management of non-cloud infrastructure such as GitHub and Datadog.


