

.webp)




Think of Terraform as a master builder who uses two essential tools to bring our digital infrastructure to life: inputs and outputs.
Input variables are our way of giving Terraform the blueprint - telling it exactly how we want our digital house to look. On the other hand, output values are Terraform’s way of providing a detailed tour of our new digital home.
This blog will explore how we can effectively utilize [.code]terraform output[.code] command to access and share details about our infrastructure, ensuring we have all we need to move in and make it our own.
What are Terraform Output Variables
Terraform output is a feature within Terraform CLI, that enables users to extract and present data from their infrastructure configurations.
These outputs can be considered the return values of a Terraform module. They allow access to resource attributes and other important information after completing the infrastructure.
Outputs are particularly valuable in scenarios where visibility into cloud resources is essential. For example, after creating an AWS S3 bucket, the output can retrieve and display the bucket's name, which other applications or services can utilize.
Terraform Output values vs Terraform Input variable
One quick and easy way to understand what outputs are and how they are used, is by contrasting them with Terraform input variables:
| terraform input | terraform output | |
|---|---|---|
| Purpose | To pass values into Terraform modules or resources, allowing infrastructure customization. | To retrieve and display information about the state of resources after deployment. |
| When They Are Defined | Before a Terraform run and used to configure resources during the run. | After resources are created and can be displayed. |
| Modifiability | The user can set input variables, which can vary between deployments. | Output values are computed based on the infrastructure and are not modifiable. |
| Inter-Module Communication | Input variables can be used to parameterize modules, allowing for different module configurations. | Outputs can be used to share information between different modules. |
| Visibility | Used to abstract away the complexity and allow users to provide only the necessary information. | Typically used to expose important information to the end-user. |
| Example Use-Case | Specifying the instance type or desired number of instances before creating EC2 instances. | Displaying the public IP address of an EC2 instance. |
Practical Examples of Terraform Output
Terraform outputs are essential for capturing information about the infrastructure. They are specifically handy for retrieving important details such as public IP addresses, DNS names, and other crucial data from the cloud infrastructure.
Outputs can be used within Terraform to share data between modules, or outside of Terraform to integrate with other systems or provide information to users.
1. Defining Output Values in Terraform Configurations
To define output values in Terraform, you follow these steps:
- Open your Terraform configuration file, typically named main.tf.
- Use the [.code]output[.code] command to define an output value. Provide a name for the output, which will be used to reference it. For example: [.code]output “public ip” {}[.code]
- Assign a value to the [.code]output[.code], which is usually an attribute of a resource that Terraform manages.
Here's an example of defining output values for the public IP address and DNS name of an AWS EC2 instance:
output "public_ip" {
value = aws_instance.env0_instance.public_ip
}
output "dns_name" {
value = aws_instance.envo_instance.public_dns
}
In this example, [.code]aws_instance.env0_instance[.code] refers to an EC2 instance defined elsewhere in the Terraform configuration.
The [.code].public_ip[.code] and [.code].public_dns[.code] are attributes of the EC2 instance that Terraform will output after the instance is created.
Terraform can expose attributes of resources through output variables, but this approach is not limited to the AWS S3 bucket resource. It can be applied to any resource Terraform manages across various providers.
The process involves identifying the desired attribute from the resource's or provider's documentation on the Terraform registry. Once identified, you can declare an output variable in your Terraform configuration that references this attribute.
Here's an example of how to use the [.code]force_destroy[.code] argument within an [.code]aws_s3_bucket[.code] resource definition:
resource "aws_s3_bucket" "env0_bucket" {
bucket = "my-unique-env0-bucket"
force_destroy = true
tags = {
Name = "My Env0 Bucket"
Environment = "Development"
}
}
This example demonstrates the use of the [.code]force_destroy[.code] argument for an AWS S3 bucket resource in Terraform.
2. Using Terraform Outputs to Retrieve Information
Once you have defined your outputs, you can retrieve them after running [.code]terraform apply[.code].
Terraform will display the outputs at the end of the apply operation in the terminal. Using the [.code]terraform output[.code] command, you can also query specific outputs after the fact.
For example, let's assume you have an EC2 instance and want to retrieve its public IP address and DNS name.
First define the EC2 instance in your Terraform configuration.
resource "aws_instance" "envo-instance" {
ami = "ami-0c55b159cbfafe1f0"
instance_type = "t2.micro"
}
Next. define the outputs for the public IP address and DNS name.
output "public_ip" {
value = aws_instance.envo-instance.public_ip
}
output "dns_name" {
value = aws_instance.envo-instance.public_dns
}
After the [.code]apply[.code] is completed, Terraform will display the outputs in the terminal.
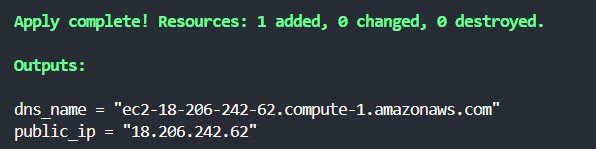
You can retrieve them anytime using the [.code]terraform output[.code] command, like so:

Following these steps will allow you to use Terraform outputs to manage and retrieve important information from your cloud infrastructure - data that could be essential for maintaining and understanding your deployments.
3. Configuring Terraform Module Output
When working with Terraform modules, outputs can expose specific values that other modules or the root module can consume.
Let's create an S3 bucket within a module and define its output, which can be accessed by the root module or any other module that calls this S3 bucket.
Your first step will be to create a directory for the S3 bucket module, such as modules/s3_bucket. Within that directory, create a file named main.tf, which defines the S3 bucket resource.
resource "aws_s3_bucket" "envo-bucket-098980" {
bucket = "envo-bucket-098980"
}
In the same modules/s3_bucket directory, create an output.tf file to define the output for the S3 bucket name.
output "bucket_name" {
value = aws_s3_bucket.envo-bucket-098980.bucket
}
Now, you can call the S3 bucket module in your root module and access its output.
module "s3_bucket" {
source = "./modules/s3_bucket"
}
In the root module's outputs.tf file, add an output block to retrieve the S3 bucket name from the S3 bucket module.
output "s3_bucket_name" {
value = module.s3_bucket.bucket_name
}
Following these steps, you created a reusable S3 bucket module with Terraform and exposed the bucket name as an output variable.

4. Using Custom Conditional Validation in Output
Terraform allows for the use of custom conditional validation within output values. This feature ensures that an output value meets specific criteria before it is exposed to the rest of your Terraform configuration or external services.
Conditional and validation rules can help prevent the propagation of incorrect or undesired data, which is especially important in automated environments like env0, where Terraform configurations might be applied as part of a CI/CD pipeline.
Suppose you have a Terraform configuration where you want to output an environment name, but only if it starts with the prefix "env0".
First, declare an input variable with the environment name.
variable "environment_env0" {
description = "The name of the environment"
type = string
}
Next, create an output that only outputs the environment name if it starts with "env0". You can use the [.code]startswith[.code] function to check the string's prefix.
output "validated_environment_name" {
description = "The environment name if it starts with 'enve*"
value = startswith(var.environment_name, "env") ? var.environment_name "Invalid name
}
In this example, the [.code]startswith[.code] function checks if the [.code]environment_name[.code] variable starts with the string "env0". If the condition is true, the output will be the [.code]environment_name[.code] value. If not, it will output the error message "Invalid name".
When you run [.code]terraform apply[.code], you must provide a value for the [.code]environment_name[.code] variable. If the provided name starts with "env0", the output will display the valid environment name.

Otherwise, it will display "Invalid name":

5. Examples of Terraform Output Flags
One of the flags you can use is [.code]-json[.code], which formats the outputs as a JSON object. This is especially useful when you want to pipe the output into other tools that can process JSON, such as jq, a lightweight command-line JSON processor.
Let's go through a step-by-step example. This example will show you how to create an S3 bucket using Terraform, output its name and ARN, and then format the output using jq.
First, you must define your Terraform configuration to create an S3 bucket.
provider "aws" {
region = "us-east-1"
}
resource "aws_s3_bucket" "envo-bucket-jq-0974" {
bucket = "my-envo-bucket"
}
output "bucket_name" {
value = aws_s3_bucket.env0-bucket-jq-0974.bucket
}
output "bucket_arn" {
value = aws_s3_bucket.envo-bucket-jq-0974.arn
}
After applying your Terraform configuration, you can use the [.code]terraform output -json[.code] command to format the outputs as JSON. Then, you can pipe this JSON output to jq for further processing.

To get the bucket name and ARN in a clean format, you can run:
terraform output -json | jq -r '.bucket_name.value, .bucket_arn.value'This command uses jq to extract the values of the [.code]bucket_name[.code] and [.code]bucket_arn[.code] outputs from the JSON, formatted by terraform output [.code]-json[.code]. The [.code]-r[.code] flag with jq outputs raw strings, removing the quotes around the values.

This method is beneficial for scripting and automation, where you might need to use Terraform outputs as input and output variables for other commands or scripts.
6. Using Terraform Output Arguments
Terraform outputs can be customized with arguments like [.code]sensitive[.code] to manage data visibility and dependencies.
The sensitive argument ensures that values like passwords or keys are not displayed in the console, marking them as sensitive in the Terraform state.
Suppose you have a local secret key that you want to output, but you want to ensure it's marked as sensitive data to prevent it from being displayed in plain text.
variable "secret_key" {
description = "A sensitive secret key"
type = string
}
output "secret_key_output" {
value = var.secret_key
sensitive = true
}In this example, the sensitive argument is true for the secret_key_output, which means that Terraform will have sensitive values that will not display their value when running terraform apply or terraform output.
Advanced Use-Cases: Multiple S3 Buckets with for_each
In Terraform, advanced output techniques often involve iteration constructs such as for and [.code]for_each[.code]loops.
These loops can be used within output blocks to dynamically generate output values based on the state of your resources.
The [.code]for_each[.code] loop, in particular, is useful when you want to create many instances of a resource and to sensitive output values for attributes in a structured way.
Suppose you want to create five S3 buckets and output their names and ARNs (Amazon Resource Names).
You can save yourself some time use the [.code]for_each[.code] loop to make these buckets and then a for loop within an output block to list their names and ARNs.
First, you'll use a [.code]for_each[.code] loop to create multiple S3 buckets based on a set of given names.
variable "bucket_names" {
description = "A set of S3 bucket names"
type = set(string)
default = ["envo-bucket1-one", "envo-bucket2-two", "envo-bucket3-three", "envo-bucket4-four", "envo-buckets-five"]
}
resource "aws_s3_bucket" "envo-bucket-for-each" [
for_each var.bucket_names
bucket = each.value
}Here, the [.code]for_each[.code] loop iterates over the set of bucket names provided in the [.code]bucket_names[.code] variable, creating a new S3 bucket for each name.
Next, you'll define an output block that uses a for loop to construct a map of the bucket names and their corresponding ARNs.
output "bucket_details" {
value = { for name, bucket in aws_s3_bucket.envo-bucket-for-each
name > bucket.arn}
description = "A map of S3 bucket names and their ARNS"
}This output block creates a map where each key is the name of a bucket, and each value is the ARN of that bucket. The for loop iterates over the aws_s3_bucket.buckets resource, which contains all the buckets created by the loop.

Using env0 Workflows to Easily Share Outputs Across Environments
In Terraform, effectively managing dependencies between modules and resources is important for creating reusable infrastructure and reusing variables in each module.
For example, if you need to use the output of an IAM role (e.g., the role's ARN), you typically reference the ARN output and pass it as an input variable to the EKS cluster.
env0 Workflows feature streamlines the process, allowing you to effortlessly share outputs from one stack in another, eliminating the need for manual transfers or supplementary tools.
Once set, env0 automatically retrieves and assigns the outputs from designated upstream environments as environment variables in the dependent environments.
Besides saving time and effort, this also enhances security by ensuring that all configurations are centrally managed and consistently updated.
Moreover, using env0 ensures that sensitive data, which sometimes can be stored in outputs, is passed in an encrypted manner (and not as plaintext). And you can also enable encryption, when using self-hosted agent.
Let's break down how this works.
Step 1: Enable Environment Output
Start by navigating to the 'Policies' tab under 'Project Settings' in your env0 dashboard and activate ‘Environment Output’. This will allow env0 to capture outputs from one environment and make them available in others.
Step 2: Create the First Environment
Set up your first environment. For instance, using this Terraform code to create an AWS S3 bucket:
provider "aws" {
region = "us-east-1"
access_key = var.aws_access_key
secret_key = var.aws_secret_key
}
variable "aws_access_key" {
type = string
default = ""
}
variable "aws_secret_key" {
type = string
default = ""
}
resource "aws_s3_bucket" "aws-bucket-env012" {
bucket = "aws-bucket-env0-1223"
tags = {
Name = "env0bucketaws12"
}
}
output "bucket_name" {
value = aws_s3_bucket.aws-bucket-env012.bucket
}
Once done, run your Terraform code to deploy this environment.
Make sure the deployment is successful and that the output [.code]bucket_name[.code] is generated. In this example, this is the output that you will use as input for our next environment.

Step 3: Capture the Output
Return to the project settings in your env0 dashboard and select the 'Variables' tab.

Create a new variable, selecting the [.code]bucket_name[.code] output from the deployment you’ve just completed.

Step 4: Set Up the Second Environment
Configure another environment, using the captured ‘bucket_name’ to set up a new resource.
provider "aws" {
region = "us-east-1"
access_key = var.aws_access_key
secret_key = var.aws_secret_key
}
variable "aws_access_key" {
type = string
default = ""
}
variable "aws_secret_key" {
type = string
default = ""
}
variable "bucket_name" {
type = string
default = ""
}
resource "aws_s3_bucket" "bucket-env0-3232" {
bucket = "${var.bucket_name}-env0343"
tags = {
Name = "Bucket 2"
}
}
In the variable section, you'll that the environment output is already auto-added to the new environment:

As you execute the Terraform code, this setup will create another S3 bucket, dynamically naming it using the first environment's output:

And that it’s, now output from the first environment and used it as the input of the second one, allowing you to easily string them together and in a continuous workflow.
Frequently Asked Questions
Q: Where are Terraform Output values stored?
Terraform output values are stored in the state file.
Q: Can we use the count argument for terraform output values?
No, you cannot directly use the [.code]count[.code] argument within an output definition in Terraform. The count argument creates multiple instances of a resource or module but cannot be applied directly to outputs.
However, when you have resources created with the [.code]count[.code], you can reference these resources in your outputs using a splat expression or other methods to aggregate or format the values from the multiple instances created.
Q: How do you store Terraform plan output?
To store [.code]terraform plan[.code] output, you can direct it to a file using the -out option with the terraform plan command, like so:
terraform plan -out=tfplanThis creates a binary file named tfplan that can be used later with [.code]terraform apply[.code]. Redirect the plan to a text file for human-readable output, but note this format is for review only and not for execution.
Q: How can you format or manipulate output values in Terraform?
In Terraform, you can format or manipulate output values using built-in functions within the output definitions in your Terraform configuration files. Here's a short example using the format function to manipulate a string output:
output "formatted_output" {
value = format("This VM has IP: %s", aws_instance.example.public_ip)
}
Terraform provides various functions, such as format, join, split, replace, and mathematical, to manipulate strings, lists, and numbers within your outputs.
Q: Can a Terraform output be a map?
In Terraform, you can define an output as a map by assigning a [.code]map[.code] value to the output's value attribute. This is useful for organizing and returning a collection of related values. For example, if you have multiple instances with their respective IDs and IPs, you can output these as a map where each instance ID is a key, and its IP is the corresponding value.
Conclusion
Terraform outputs are essential for effectively managing and disseminating information within Infrastructure as Code (IaC), offering insights such as IP addresses and DNS names.
Unlike input variables that set up resource configurations, outputs facilitate the external sharing of data.
Advanced methods like loops and conditional outputs enhance their practical application in extracting key infrastructure details. Furthermore, output arguments, notably 'sensitive', improve security measures.
Incorporating Terraform outputs into automation tools like env0 can serve as an effective way to manage dependencies and streamline complex deployments and other infrastructure management processes.

![Using Open Policy Agent (OPA) with Terraform: Tutorial and Examples [2026]](https://cdn.prod.website-files.com/63eb9bf7fa9e2724829607c1/69d6a3bde2ffe415812d9782_post_th.png)
