
.webp)



.png)
The rise of Infrastructure as Code has revolutionized the management of infrastructure and the way we provision and maintain platforms for application deployment. Rather than manually deploying infrastructure through a CLI or GUI, we can now treat our infrastructure in the same way we treat our applications.
We can leverage common software development paradigms like source control repositories, modules and libraries, and automation pipelines. At the same time, we must bear in mind that application and infrastructure deployments are different, and not all practices typical of software development map neatly to infrastructure deployment. Infrastructure deployment and management has unique challenges and features that require an adjustment in code maintenance and automation.
In this article, we’ll examine how to treat infrastructure as code like software and the implications that has on continuous integration and delivery.
Infrastructure as Code is CODE
Even though code is right there in the name, it’s not uncommon for operations professionals to treat IaC like another script they have in their repertoire, stashed away in someone’s home directory and passed around through a series of emails and file shares across the organization. But to truly leverage the power of IaC, we need to treat it like a software development process. What does that entail? Let’s review some key features:
Source Control
Your infrastructure as code needs to be stored in a repository on a centralized version control system of some kind. At a minimum, this allows you to track changes to the code and roll back to a previous version if needed. It also unlocks a ton of other features, including the ability of other team members to contribute, share, and use your IaC on their own project. Your repository can serve as a module or library for consumption by other members of the organization, allowing you to develop a standardized approach for common deployment patterns.
Scanning and Testing
Having your infrastructure defined in code means that the code can be scanned and evaluated in many ways. It starts with simply checking the basic syntax of the code to ensure that the defined resources, methods, and variables are logically valid. For instance, you could easily scan to ensure that a property you reference for a virtual machine is actually valid.
Beyond simple syntactic testing and logical validation, code can also be statically analyzed to ensure compliance with regulations, company standards, and security best practices. You can flag code that opens up port 22 to the world or makes a storage account public. It’s also possible to deploy your code in a testing environment and validate the functionality of your infrastructure against its intended purpose.
Automate testing and deployment
Once your infrastructure as code is stored in source control, you can use the hooks provided by that source control to kick off workflows for continuous integration, delivery, and deployment. Each of those workflows can be defined in pipelines that are stored alongside the infrastructure code and maintained through the same source control process. Within pipelines for continuous integration or continuous delivery, you can incorporate the testing and validation detailed earlier, adding in logic that requires the code to pass these tests before it can be promoted to production.
Through that lens of source control, testing, and automation, we can examine the continuous integration and delivery processes and highlight how IaC differs from typical application development and deployment.
Continuous Integration
Continuous Integration refers to the process in software development of merging a working branch into the main branch. The general recommendation is to have short-lived feature branches, along with a single well-defined main branch. This concept maps well to infrastructure as code, especially if you plan to separate out your configuration data from your code. Changes made to the code should be reflected in all environments that use the code, whereas configuration data customizes the deployed infrastructure for a given environment.
When you’re first getting started with infrastructure as code, you might be tempted to store your IaC in the same repository as your applications code, also known as a monorepo. This may work well initially, but becomes difficult to maintain as the application and infrastructure tend to change at different rates and require separate testing processes. The recommended practice is to maintain separate repositories for application and infrastructure code with loose coupling and dependency inversion.
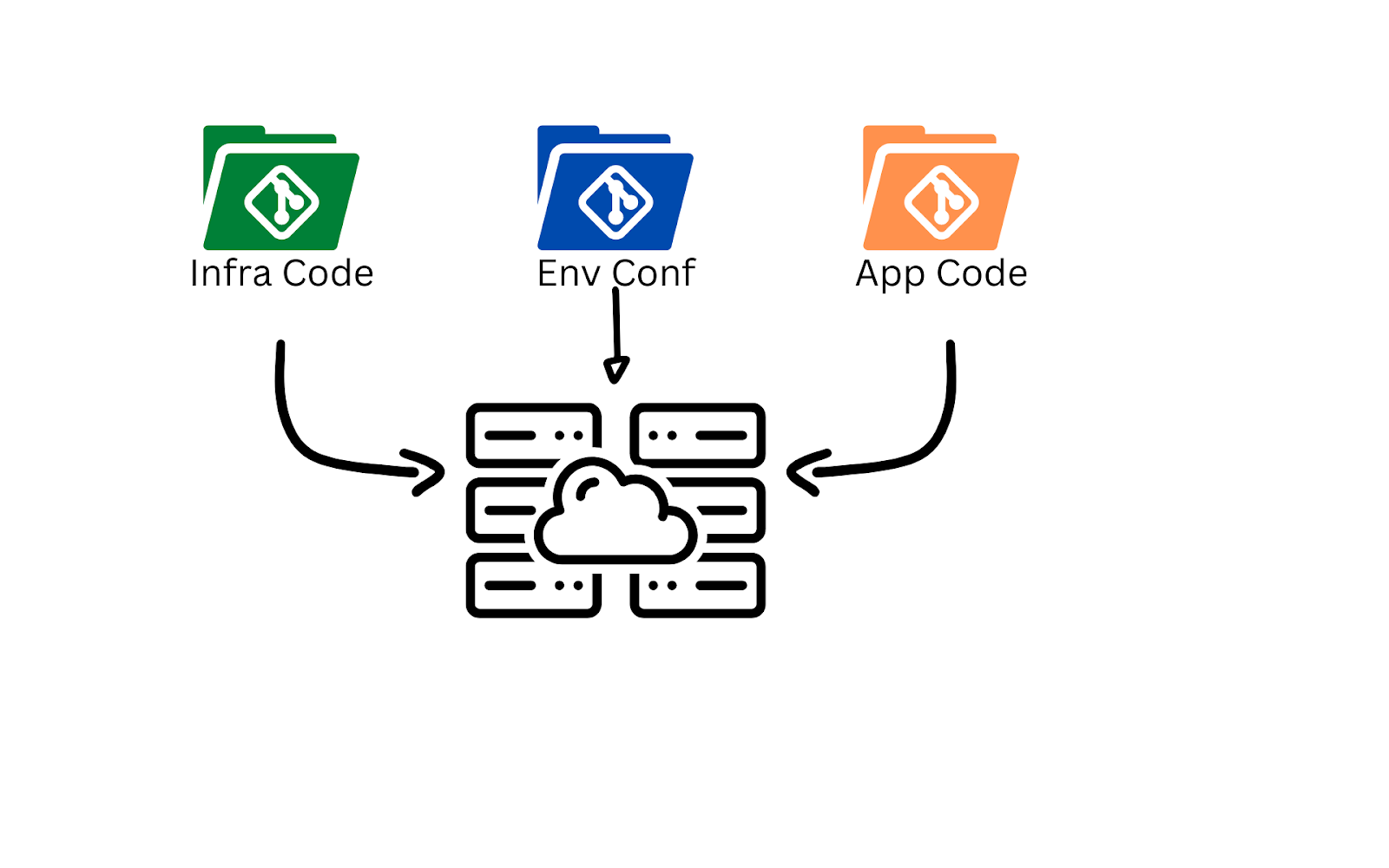
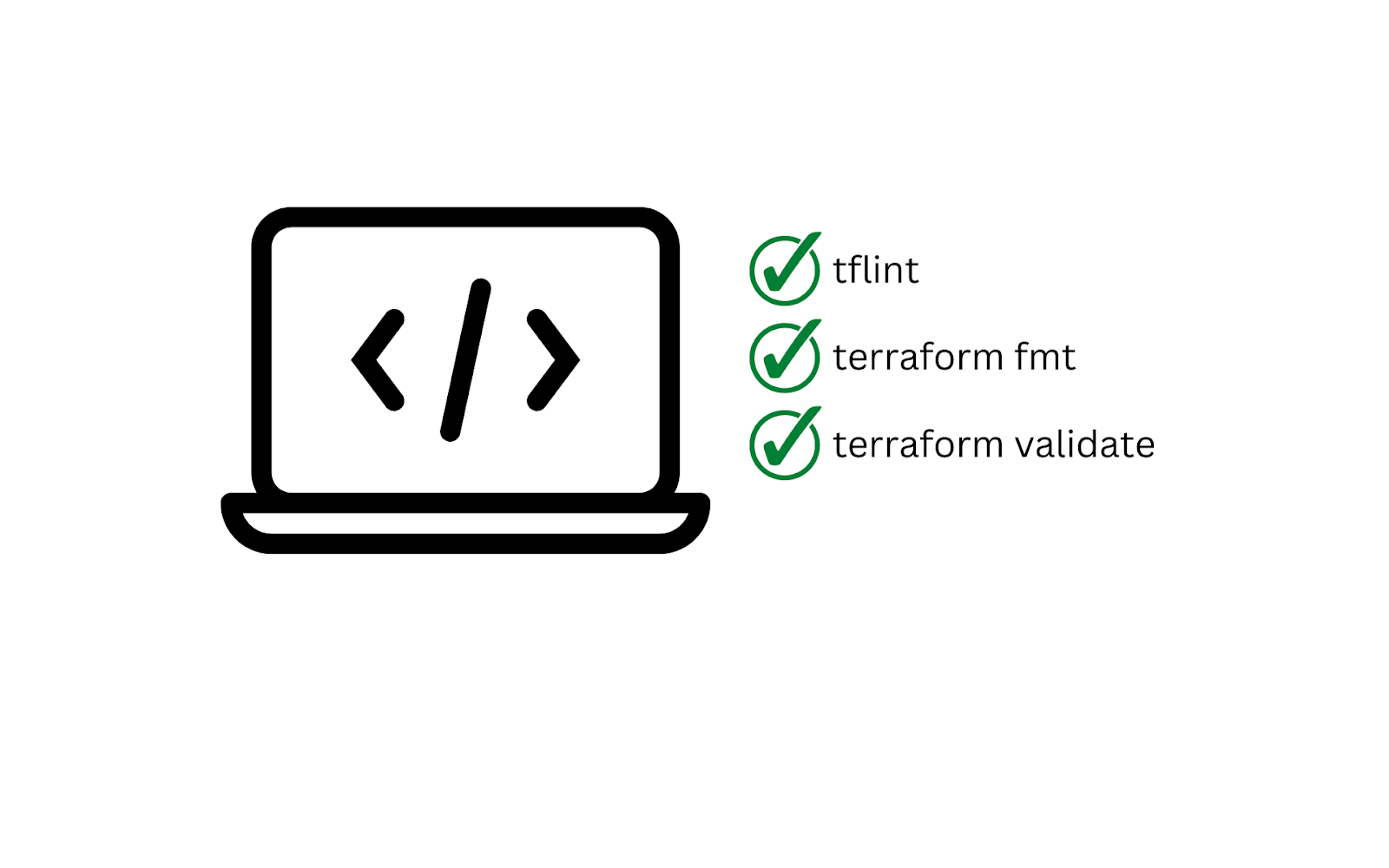
Bearing this separation in mind, what does a typical CI process look like for infrastructure as code? The process starts when a commit is made to the repository at the local workstation level, before the change is pushed to the centralized repository. At this early stage, you are trying to empower the developer to write infrastructure code that is formatted properly, syntactically correct, and logically valid.
In the case of Terraform, this can be accomplished by using a linter in the code editor, the `terraform fmt` command, and the `terraform validate` command. This is similar to the basic checks one would expect an application developer to run before they pushed a new feature branch.
Once a commit is pushed to the centralized repository, the continuous integration process kicks off in earnest, typically running similar validation as the develop - trust, but verify - and blocking a pull request from being opened until all checks have passed.
Depending on the language used for the infrastructure code, your developer may also wish to write some unit tests that validate the functions inside the IaC. Often this is unnecessary, as the unit testing is encapsulated by the infrastructure provider, but if you are using a CDK with a general purpose programming language, then unit tests are desirable to test any custom functions or methods.
Integrating the code into the main branch will involve more in-depth testing and validation, including scanning the code with static analysis tools to verify adherence to policies, organization standards, and security requirements. Some common tools for accomplishing this goal are Checkov, tfesec, and Open Policy Agent (OPA). Each tool compares the infrastructure code to policies defined by the vendor or organization, and returns the test results with a pass/fail metric.
.png)
When a feature branch is integrated (merged) into the main branch, the next step in a typical continuous integration process would be building a new version of the application based on the updated code. However, this is a key place where infrastructure as code differs. IaC is not compiled and does not produce a binary, zip, or other similar artifact. There is no build process per se. Instead, the most common next step is to move on to the continuous delivery process.
Continuous Delivery
In the world of application development, the build artifacts from the CI pipeline are deployed to a testing environment and validated for functionality before being made available to the production and lower environments. The parallel in IaC would be the deployment of code to a testing environment to validate the desired functionality of the updated code using something like kitchen-terraform or Terratest.
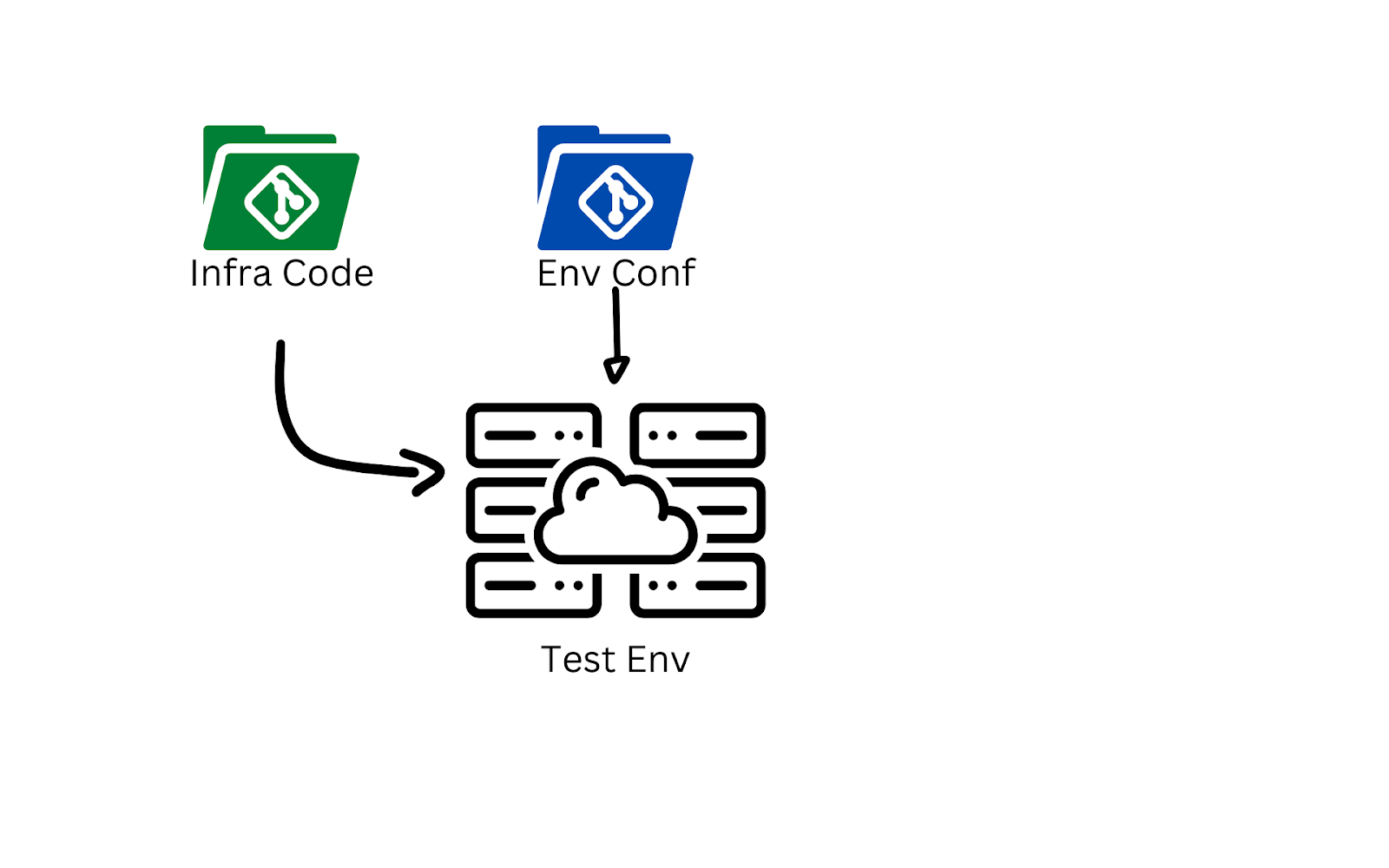
A key difference between application and infrastructure deployment, for testing or production, is how the new application or infrastructure code is delivered to the target environments. The deployment of infrastructure requires proper credentials to create resources on the target provider.
For instance, deploying a test environment on Microsoft Azure requires the pipeline to have credentials in Azure AD and permissions to create resources in the testing subscription. Handling sensitive credentials properly is a challenge for any pipeline solution, and it’s one you’ll need to consider when automating your testing and deployment.
Once functional testing is completed, the next step in the delivery process is a dry-run against production and lower environments to examine the impact of the code changes. This is another major difference between application CD and infrastructure CD.
With an application update, you can perform blue/green deployments or canary roll-outs, and monitor the performance and stability of your updated application. Infrastructure code doesn’t have a parallel. Instead, the most common procedure is to perform a dry-run against each environment to assess what changes will be made by the updated code.
The results of the dry-run can be analyzed programmatically to determine the next step in the pipeline:
- Automatically promote the changes to production
- Require manual approval for promotion
- Deny promotion due to policy violations
There are many testing frameworks out there you can use to analyze the results of the dry-run, but Open Policy Agent is quickly becoming a standard because of its flexibility.
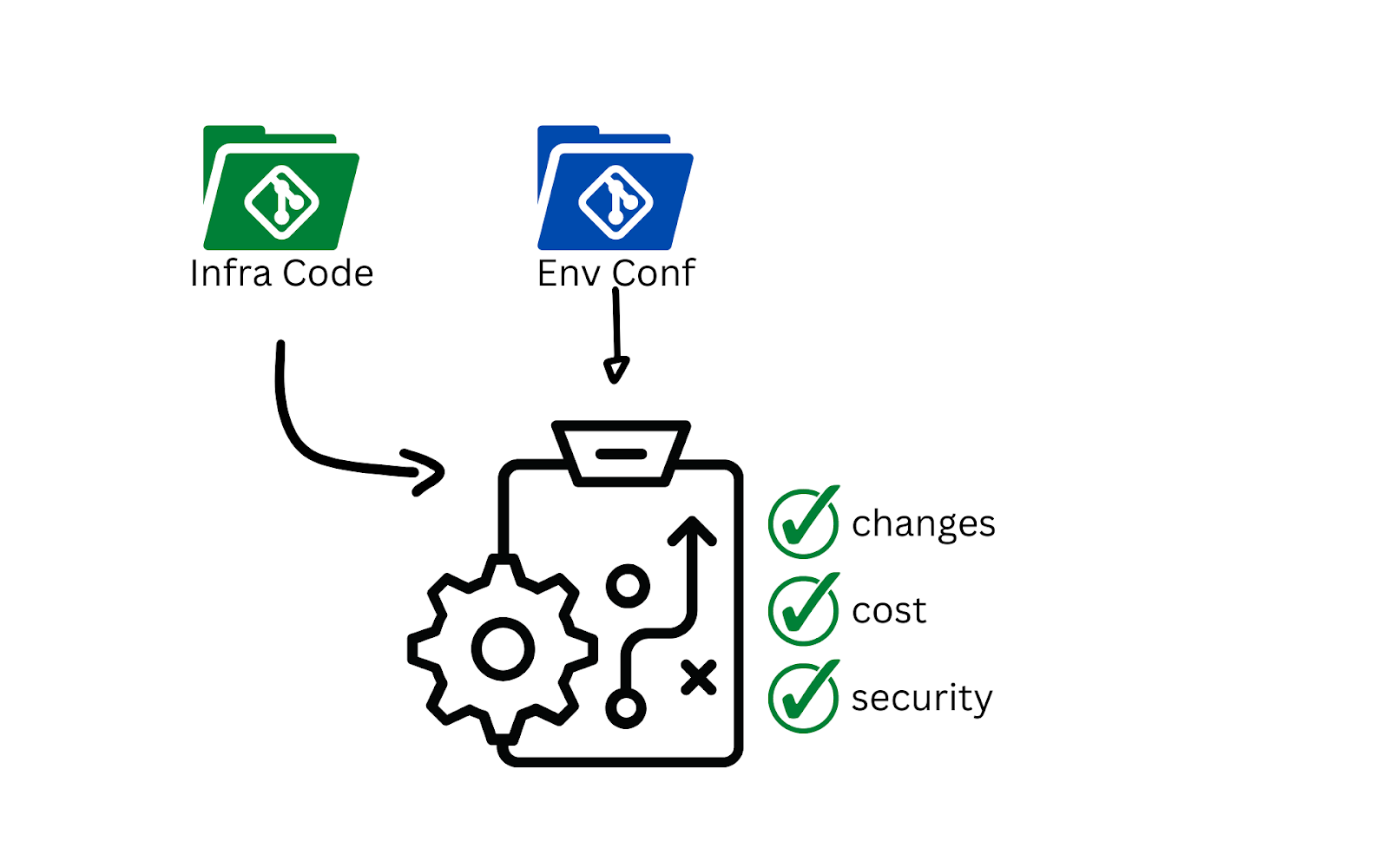
An examination of the dry-run results should include, but is not limited to:
- The number of alteration being made to existing resources
- The number of deletions and creations
- Estimated cost of updated deployment
The last bullet point is especially important to call out, since once again this is a major difference between application and infrastructure code updates. An update to your application is unlikely to have an immediate and obvious impact on the cost of operations.
However, infrastructure code can blow out your cloud bill if you’re not paying attention. Pick the wrong virtual machine size or storage class, and you could have quite a surprise coming for you at the end of the month.
Fortunately, you can integrate cost estimation with a tool like Infracost, and flag any deployment that exceeds a certain amount or is a certain percentage more expensive than the current deployment.
Updating your infrastructure using IaC and CI/CD pipelines isn’t the end of the journey. You’ll still need to integrate with the application deployment process and continually monitor your infrastructure for potential issues. But now you’ll actually have time to do that, since you’ve automated away the tedious and error-prone process of deployment and updates.
Conclusion
Treating your infrastructure definition as code and implementing CI/CD pipelines to assist with integration and deployment is going to make your life simpler, faster and easier to maintain. There should be a single source of truth for your environments, separating the code from the configuration. You should automate the testing of your infrastructure code during both CI and CD to enable consistent and compliant results. Your testing will be a combination of static analysis and functional testing for validity, security, compliance, and cost.
Pulling all these elements together is akin to keeping your tools neatly in a toolbox. A toolbox with the correct layout for your working practices, that helps you to work the way you want to, at the speed you need.


