.webp)
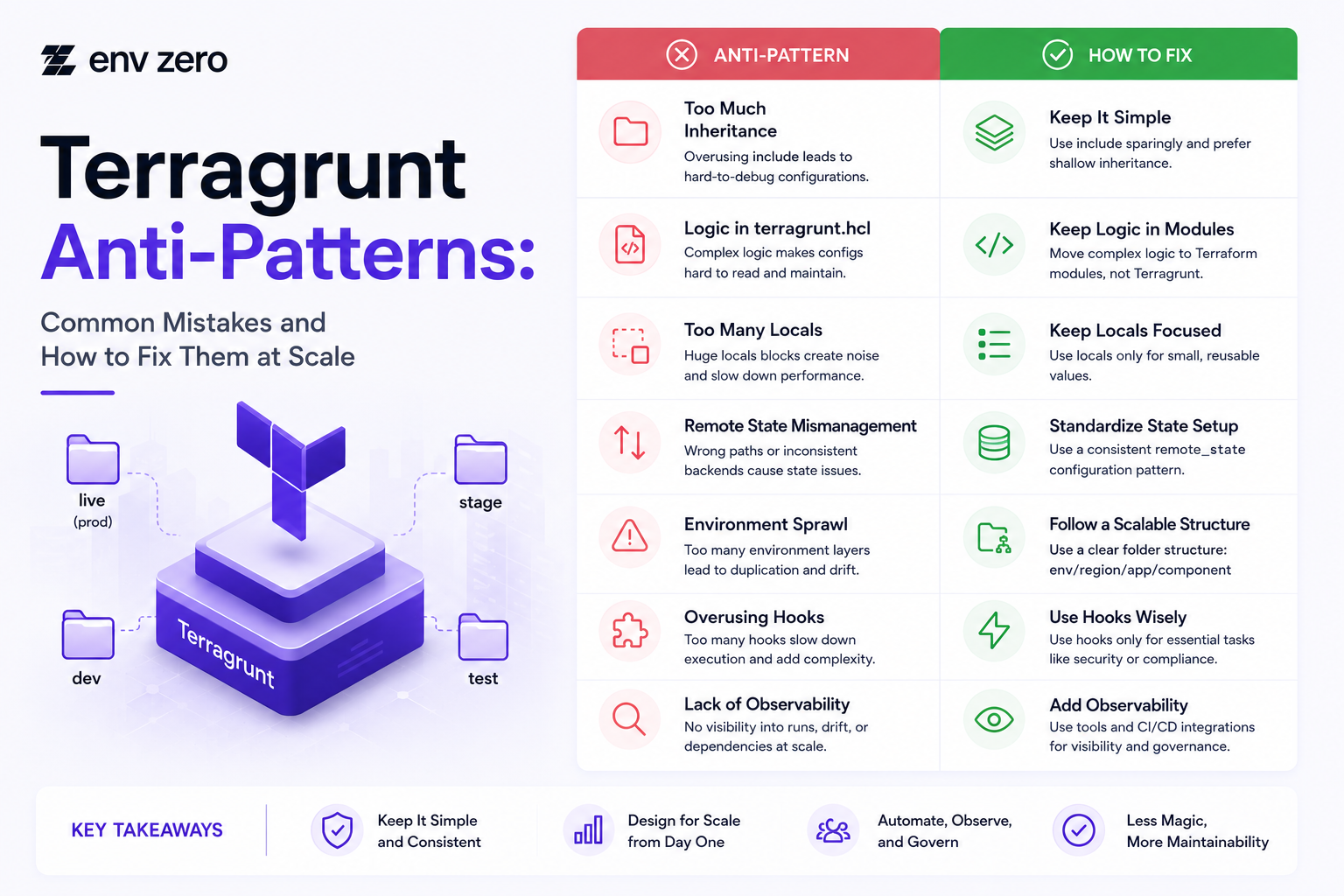
Terragrunt management becomes harder when teams scale from a few Terraform wrappers to dozens of environments, modules, dependencies, and team-owned workflows.
Terragrunt helps teams keep Terraform and OpenTofu configurations DRY, but it does not automatically prevent poor structure, hidden dependencies, unsafe run-all usage, or unclear ownership.
The problem usually appears slowly. A team starts with clean shared configuration. Then more environments are added. More teams copy existing folders.
Dependencies grow. Production workflows become harder to review.
Eventually, Terragrunt becomes the layer everyone depends on but only a few people fully understand.
This guide explains common Terragrunt anti-patterns and how platform teams can fix them at scale with better structure, ownership, and governance through env0’s IaC Platform & Terraform Automation service.
Treating Terragrunt as a Terraform Replacement
A common mistake is misunderstanding what Terragrunt is. Terragrunt is not a replacement for Terraform.
It is a wrapper that helps teams organize Terraform or OpenTofu configurations, reduce repeated settings, manage dependencies, and coordinate workflows.
The terragrunt vs terraform distinction matters because Terraform is still the engine that provisions infrastructure.
Terragrunt helps manage how that engine is used across environments.
The fix is to define Terragrunt’s role clearly. Use Terraform or OpenTofu modules for reusable infrastructure logic.
Use Terragrunt for environment configuration, shared settings, remote state patterns, and dependency orchestration.
This keeps module design and environment management from becoming mixed together.
Copying Environment Folders Instead of Sharing Configuration
Terragrunt is often adopted to avoid duplication, but many teams still copy full dev folders into staging and production. Over time, each environment drifts into its own version of the truth.
This anti-pattern creates hidden differences. A setting may be updated in dev but missed in production. A module version may be pinned differently across environments.
A backend or input value may be copied manually and forgotten. The fix is to place shared settings at the highest level where they apply.
Use environment-level files only for values that truly differ between dev, staging, and prod. Keep common provider assumptions, remote state patterns, naming conventions, and shared inputs centralized.
Creating Units Without Clear Ownership
Terragrunt units are useful because they keep deployable infrastructure pieces separated. But when units have no owner, troubleshooting becomes difficult.
A unit may represent networking, databases, identity, Kubernetes, application infrastructure, or monitoring.
If no team owns that unit, no one is clearly responsible for updates, reviews, drift, or incidents.
The fix is to assign ownership to every unit. Ownership should include review responsibility, lifecycle maintenance, escalation paths, and production approval authority.
In larger organizations, ownership should also be visible in repository metadata, documentation, or platform workflows.
env0 helps teams connect Terragrunt workflows to RBAC, approvals, and audit trails so ownership is not only written in documentation.
Overusing Terragrunt Dependency Chains
A terragrunt dependency lets one unit reference outputs from another unit. This is useful, but dependency chains can become difficult to understand at scale.
The anti-pattern appears when many units depend on many other units across environments or teams.
A small change in one foundational unit may affect unrelated workflows. Plans become harder to review because the dependency graph is not obvious.
The fix is to keep dependencies intentional and visible. Shared foundations such as networking, identity, and account baselines should be clearly separated from application-level units.
Cross-team dependencies should be documented and reviewed more carefully. Production dependencies should have stronger approval rules.
Using run-all Without Managing Blast Radius
Terragrunt run-all can be powerful because it helps execute Terraform or OpenTofu commands across multiple modules.
But using it casually can create risk, especially in production. The anti-pattern is running broad commands across too many units without understanding dependency order, expected changes, or blast radius.
A command intended for one layer may produce plans across several unrelated units.
The fix is to limit broad execution to controlled workflows. Use smaller scopes where possible. Review plans carefully before apply.
Apply stronger approval rules for production. Teams should also avoid making run-all the default path for every change.
env0 supports Terragrunt run-all workflows while giving platform teams control over templates, approvals, RBAC, and auditability.
Treating Terragrunt Stacks as Dumping Grounds
Terragrunt stacks help teams group related units into higher-level workflows.
They are useful for application environments, account baselines, shared services, and regional deployments.
The anti-pattern happens when stacks become large collections of unrelated units.
This makes stacks harder to reason about and increases deployment risk.
The fix is to give every stack a clear operational purpose. A stack should represent a meaningful boundary, such as a production application environment or a shared platform layer.
Each stack should have an owner, lifecycle, dependency expectation, and approval model.
Stacks should simplify infrastructure management, not hide complexity inside a bigger wrapper.
Mixing Platform-Owned and App-Owned Infrastructure
Another common anti-pattern is mixing platform-owned and application-owned resources in the same workflow without clear boundaries.
This creates confusion around who can approve changes and who is responsible when something breaks.
For example, networking and identity may be platform-owned, while application queues and service-level storage may be app-owned.
If both are managed through the same unit or stack, access and approval rules become unclear.
The fix is to separate ownership boundaries. Platform-owned foundations should have stricter controls.
Application-owned infrastructure can often support more self-service. This structure allows developers to move faster without giving them unsafe access to shared production foundations.
Ignoring Drift and Cost After Apply
Terragrunt helps organize infrastructure changes, but it does not remove the need for ongoing visibility.
Real infrastructure can still drift when someone changes resources manually. Costs can still grow when environments are over-provisioned or forgotten.
The anti-pattern is treating a successful apply as the end of governance. In reality, teams need visibility after deployment.
The fix is to monitor drift, review cost impact, and maintain audit trails.
Platform teams should know what changed, who approved it, and whether infrastructure still matches the desired configuration.
env0 helps teams manage drift detection, cost visibility, and audit logs as part of governed Terragrunt workflows.
Relying on Local Terragrunt Runs for Team Workflows
Local Terragrunt usage is helpful for learning and testing, but it becomes risky when used as the main team workflow.
Local runs can bypass approvals, create inconsistent tool versions, and reduce visibility into production changes.
The fix is to move Terragrunt execution into governed workflows.
Developers can still work with Terragrunt, but production plans and applies should happen through a controlled platform with RBAC, approvals, logs, and policy checks.
This is especially important after teams install Terragrunt across many developer machines.
Installation should be standardized, but execution governance should not depend on every developer following manual rules.
How env0 Helps Fix Terragrunt Anti-Patterns
env0 helps platform teams manage Terragrunt at scale by adding governance around the workflows Terragrunt enables.
Teams can use templates, approval workflows, RBAC, drift detection, cost visibility, audit logs, and self-service controls.
This helps organizations avoid the common trap of treating Terragrunt structure as the full platform.
Terragrunt can organize Terraform and OpenTofu workflows, while env0 provides the governance layer needed to scale those workflows safely.
For teams managing multiple environments and teams, env0 makes it easier to standardize Terragrunt usage without forcing every team to build its own CI/CD and approval process.
Conclusion: Terragrunt Scales Best With Clear Boundaries
Terragrunt is valuable because it helps teams reduce duplication and organize infrastructure across environments.
But at scale, the biggest risks come from unclear ownership, hidden dependencies, broad run-all usage, oversized stacks, and weak workflow governance.
The solution is not to abandon Terragrunt. The solution is to structure it carefully and manage it through a platform layer.
With env0, platform teams can keep the benefits of Terragrunt while adding the controls needed for enterprise infrastructure delivery.
Build Governed Terragrunt Workflows With env0
env0’s IaC Platform & Terraform Automation service helps teams manage Terragrunt workflows with templates, approvals, RBAC, drift detection, cost visibility, audit logs, and self-service automation.
Talk to env0 to identify Terragrunt anti-patterns and build safer workflows across teams, environments, and infrastructure layers.
FAQs
What is Terragrunt management?
Terragrunt management is the practice of organizing, running, and governing Terragrunt workflows across teams, environments, modules, dependencies, and production infrastructure.
What is the most common Terragrunt anti-pattern?
One common anti-pattern is copying environment folders instead of sharing configuration properly. This creates duplication, drift, and inconsistent behavior across dev, staging, and production.
Is Terragrunt a replacement for Terraform?
No, Terragrunt is not a replacement for Terraform. Terraform or OpenTofu provisions infrastructure, while Terragrunt helps organize configuration, dependencies, state patterns, and multi-environment workflows.
Why can Terragrunt dependencies become risky?
Terragrunt dependencies become risky when they create hidden chains across teams or environments. This makes plans harder to review and increases the chance that one change affects unrelated infrastructure.
When should teams use Terragrunt stacks?
Teams should use Terragrunt stacks when related units need to be grouped into a meaningful operational workflow, such as an application environment, account baseline, or shared services layer.
How does env0 help with Terragrunt anti-patterns?
env0 helps teams govern Terragrunt workflows with templates, approvals, RBAC, drift detection, cost visibility, audit logs, and self-service controls, reducing the risk of unmanaged workflows at scale.